
“Cloud servers are cattle, not pets!"
So I have been working with configuration management for a while, recently I have been switching between Ansilble and Salt Stack. After creating a Salt Stack for a previous employer in AWS (see below diagram), I have fallen for this configuration management system. As you may have noted, I am using Python based, YAML configured systems because this is where I am comfortable. These systems are easily extendable, the configuration files are easy to read for anyone and they are both awesome. Salt, ultimately, has won over purely based on requirements to support my previous employer’s legacy applications. I’ve become very familiar with it and I am sticking with what I am comfortable with.
Why do we use configuration management? The main answers in my mind are automation, repeatability and accountability. If I need to create a new machine (either because a previous one has failed or I need extra compute capacity), I don’t have to do a lot. I bootstrap, Config Management does the rest. I can do this to one machine or a hundred machines and the resulting output will always be the same. I can track all configuration changes in version control systems such as git, so there is a level of accountability for change.
Another final point to mention is that configuration management is idempotent. What does idempotent mean? An example of an idempotent process is washing your dog, wash him once or wash him twice, the outcome is the same: a clean dog. The opposite of an idempotent process is an incremental process, I feed the dog once he is healthy, feed him twice and he gets fat. I can apply a configuration once or a hundred times and the output is always the same. This isn’t always the case with custom shell scripts used for provisioning, these are often written to be run once.
Roles based on hostname
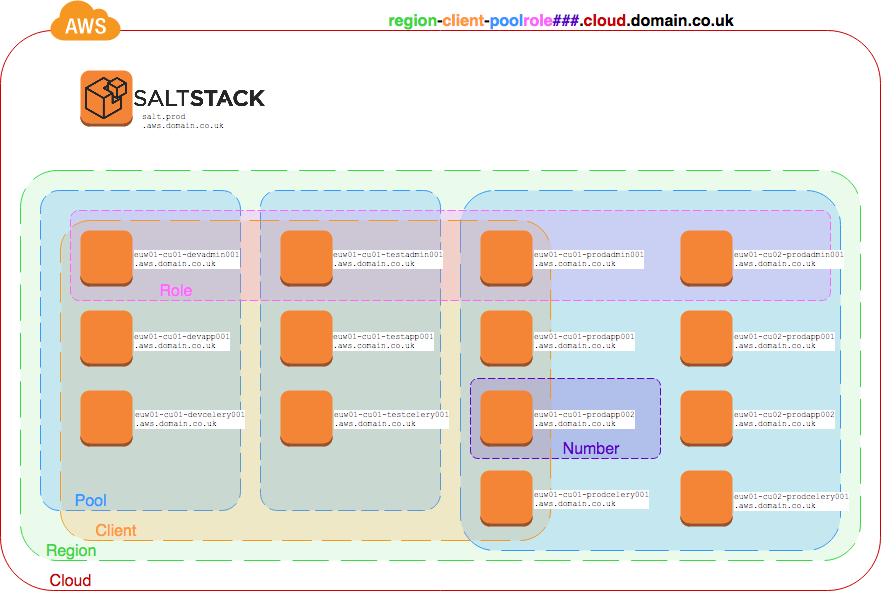
My previous employers legacy cloud applications used to be configured with CFEngine3. Arguably not the easiest system to work with, but it was one of the first configuration management systems available. As our main cloud environment hosted multiple customers, each host with a different role, a convenient way of tracking the role and cost centre for each VM was vital. This needs to be machine readable and human readable due to the sheer scale of VMs in use. With CFEngine3 it was identified the best way of assigning a role to a VM was via the hostname - this was useful for us human SysAdmins/Developers too because we could easily find what we needed. Moving to AWS, it made sense to keep this convention but find a way of applying it into SaltStack.
From our naming convention, we had the ability to automatically set up grains to help in targeting our systems for configuration.
When a minion connects to our Salt Master, the machine is seen as a ‘base’ configuration - the initial highstate run is to perform the following:
- Set the grains of the minion based on hostname
- Add the host to a pool
- Install base packages and configuration that apply to ALL hosts
- Set up a cron job to check for configuration updates hourly
- Set up an
attask to perform the next highstate run.
Now that the initial highstate has been called, the minion will have it’s configuration applied from one of the 3 pools (dev/staging/prod).
Below is a partial extract of the configuration showing base (which was our initial configuration before grains had been established from hostname), and our prod with a few sample roles within our infrastructure.
base:
'*':
- defaults
- defaults.at
- defaults.cron
- defaults.grains
prod:
'*':
- defaults
- defaults.cron
- defaults.grains
- defaults.ntp
'G@g_client:infra and G@g_role:fileserver':
- fileserver.nginx
'G@g_client:infra and G@g_role:blogs':
- defaults.ssl
- blog.users
- blog.nginx
- blog.docker
'G@g_client:infra and G@g_role:automation':
- defaults.ssl
- automation.docker
- automation.docker.api
- automation.docker.codereviewbot
'G@g_client:infra and G@g_role:pypirepo':
- defaults.ssl
- pypi.users
- pypi.nginx
- pypi.docker
[...]
Let’s say we have the host euw01-infra-prodautomation001.aws.domain.co.uk - following the initial salt highstate run, we now have a host that will be configured from prod: 'G@g_client:infra and G@g_role:automation. The following states will be applied:
- defaults.ssl (our SSL configuration including access to SSL repository)
- automation.docker (Installation of docker for automation servers)
- automation.docker.api (Our API for CLI tools to interact with AWS during deployment).
- automation.docker.codereviewbot (Our bot for issuing code review requests)
And just like that, within 10 minutes of spinning up an EC2 in AWS it can be configured precisely as needed based purely on the hostname of the server.
Home Use
Motivation
Having invested a lot of time in Salt I decided that I should probably continue to practice what I preach. Having previously experienced data loss at home first hand, having to restore from backups and needing to install all my applications all over again, I thought it was time I actually used this great tool for keeping my own systems configured.
I also (on the odd occasion) forget to apply the odd security update. Who doesn’t. My Salt configuration will ensure that key security updates are done on time.
Another key motivator is to continue that pets vs. cattle mentality to my own infrastructure, where I should be able to re-create my desktop environment, or my Raspberry Pi Bastion fairly quickly if it fails for whatever reason.
I would like to note that you can run Salt decentralized, however I have chosen to keep it centralized so that the configuration is always at the same version across all machines.
Result
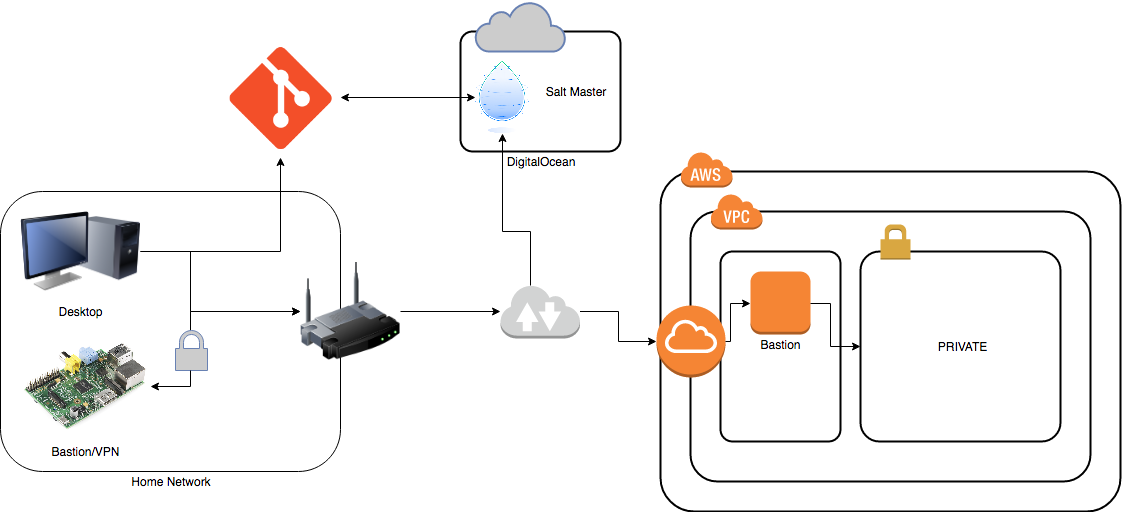
Over the space of 2 months (a couple of hours every weekend), I’ve created a Salt configuration that describes the main devices in my personal infrastructure:
- Desktop computer
- Raspberry Pi Bastion/VPN Server
- Webserver (running Ghost on Docker)
- Bastion in the public subnet of my AWS lab.
All of the above is described in a Vagrantfile that can be spun up and trashed as a development environment for testing before deploying to production.
I do not have a naming scheme for hostnames that can be programmatically dealt with, so I have had to create a map that takes hostname and applies the appropriate grains to that minion. These grains then dictate what the configuration of the minion will be. I am still using the same definitions as before: region, cloud, pool, role, etc.
{% raw %}
# hosts.map
{% set host_id = salt['grains.filter_by']({
'helios': {
'region': 'euw02',
'cloud': 'aws',
'pool': 'prod',
'role': 'bastion',
},
'icarus': {
'region': 'local',
'cloud': 'lan',
'pool': 'prod',
'role': 'bastion',
},
'daedalus': {
'region': 'local',
'cloud': 'lan',
'pool': 'prod',
'role': 'desktop',
},
'morpheus': {
'region': 'lon',
'cloud': 'digitalocean',
'pool': 'prod',
'role': 'webserver',
},
'unknown': {
'region': 'unknown',
'cloud': 'unknown',
'pool': 'base',
'role': 'generic',
},
}, grain='hostname', default='unknown') %}
{% endraw %}
Problems, lessons learnt
This is my initial attempt at configuration management at home. Upon reflection I have discovered the following issues that will affect my decisions going forward:
- A 512 MB RAM Rasberry Pi Model B is underpowered for running Salt-minion and a VPN at the same time.
- A Salt Master ideally needs at least 1 GB RAM.
- Vagrant is OK for testing, but you cannot test a Rasbperry Pi’s performance in VirtualBox.
- Pillars are vital, and once Salt becomes more friendly with HashiCorp’s Vault this will become much better for storing secrets - especially when backed with something like S3 storage. I am currently using GPG2 encrypted pillars which is slow and manual to manage.
- Configuration management tools are aimed at server markets, desktop environments require a lot more work to configure to your liking. Often it is easier to create a base config and further config (wallpapers, GNOME plugins) can be done to user taste.
- Salt has got some limits on minion OS support. openSUSE doesn’t seem to work fantastically for the latest release.
I will continue to work with Salt and see where I can make performance improvements and tighten my configuration, but I might resort to adopting Ansible for reasons I will explain at a later date.
Going forward I can test the effectiveness of my configuration management by performing some infrastructure changes and restructuring. The changes I am going to test will involve:
- Changing my Raspberry Pi bastion to run OpenBSD/FreeBSD, it will be interesting to see how Salt handles either of these OS.
- Re-creating my web server with the exact configuration I have in configuration management.
- Updating my Debian 8 desktop to Debian 9 or moving to Ubuntu once GNOME is mainstream (or just going for UbuntuGNOME 16.04).
At a later date (once my configuration is more “stable”) I shall release the source code to GitHub.